Pravda se jako nejvyšší hodnota i největší ctnost line celými lidskými dějinami. O její nalezení a výklad se snaží všechna náboženství, filosofické směry i věda. Máloco má v lidské kultuře větší roli než pravda. Proto jsem se vždycky styděl položit dvě zcela přízemní a zdánlivě samozřejmé otázky: “Co to vlastně je?” a ještě důležitější “K čemu je to dobré?”, jejichž odpovědi vy vysvětlovali, proč je pravda pro lidi tak strašně důležitá, že jí zasvěcují celý život a hynou po milionech. Vážně - jaký je smysl pravdy? Kde je v ní nějaká hodnota?
I tento článek je překvapivě hlavně o programování. Když se mnou ale vydržíte, uvidíte (i jako neprogramátoři), že trochu osvětluje i ty otázky filosofické. Ne, že bych na ně v programování nalezl definitivní odpovědi, ale už jen to, že se v něm dají ukázat vůbec nějaké praktické příklady, je víc, než jsem nalezl kdekoli jinde. Nebudu vykládat nic převratného, chci jen ukázat programátorům důvěrně známé věci z netradičního úhlu pohledu.
Tento článek je rozšířená textová verze mé přednášky z nekonference jOpenSpace 2021.
Samodetekující a samoopravné kódy
Než se dostanu k jádru věci, musím zopakovat jednu látku, která je sice standardní součástí vysokoškolského kurikula počítačové vědy, ale mnoho lidí se s ní v praxi nesetká tak dlouho, až si z ní nepamatují prakticky nic. Jedná se o část matematického modelu komunikace, která se zabývá chybami v přenosu informace. Bez větší teorie zkusím ukázat na příkladu (pokud se v problematice vyznáte, klidně přeskočte na další kapitolu).
Dejme tomu, že chceme poslat zprávu binárně zapsanou jako 1101 (pokud vás děsí binární čísla, představte si to jako zprávu v morseovce, kde 0 je tečka a 1 je čárka), ale při přenosu dojde vlivem šumu k chybě a zpráva je přijata jako 1111.
Pokud si chceme být jistí správným přenosem zprávy, můžeme jí pro jistotu poslat třeba dvakrát, tedy 1101 1101. Pokud dojde ke stejné chybě jako v předchozím odstavci, je přijata zpráva 1111 1101 a když příjemce vidí, že nepřijal dvakrát to samé, ví, že při přenosu došlo k nějaké chybě. Zdvojení zprávy je tedy příklad samodetekujícího kódu.
Můžeme chtít víc než jen detekovat, že došlo k chybě. Když pošleme zprávu třikrát a opět dojde k jedné chybě 1111 1101 1101, dá se ze shodnosti druhého a třetího opakování usoudit, že chyba byla ve třetím znaku prvního opakování. Ztrojení je tedy příklad samoopravného kódu.
Chybu ve zprávě můžeme tedy detekovat nebo dokonce opravit za cenu redundance přenášené informace. Ztrojení zprávy představuje velkou redundanci na to, že dovoluje spolehlivě opravit pouze jednu chybu. Matematici přišli s mnohem efektivnějšími postupy (kódy), které dovolují detekovat i opravovat zadané množství chyb s mnohem menší redundancí. Jedním z nich je například Hammingův kód.
Hammingův kód
V Hammingově kódu se naše zpráva 1101 zakóduje (opět si nepředstavujte víc než morseovku) jako 1010101. Netřeba teď řešit podle jakých pravidel se kam vkládají jaké redundantní znaky, pro názornost jsem je jen vyznačil modře, aby bylo vidět, jak málo redundance tam je proti třeba ztrojení.
Při příjmu hammingova kódu se provádí jednoduchá maticová operace, která počítá takzvaný “syndrom”. Pokud je syndrom 0, zpráva byla přijata v pořádku. Pokud není 0, zpráva byla přijata s chybou a číslo syndromu přímo označuje pozici, kde chyba nastala. V našem příkladu, když opět dojde k chybě z předchozích odstavců 1010111, bude výpočet syndromu podle wikipedie vypadat takto:
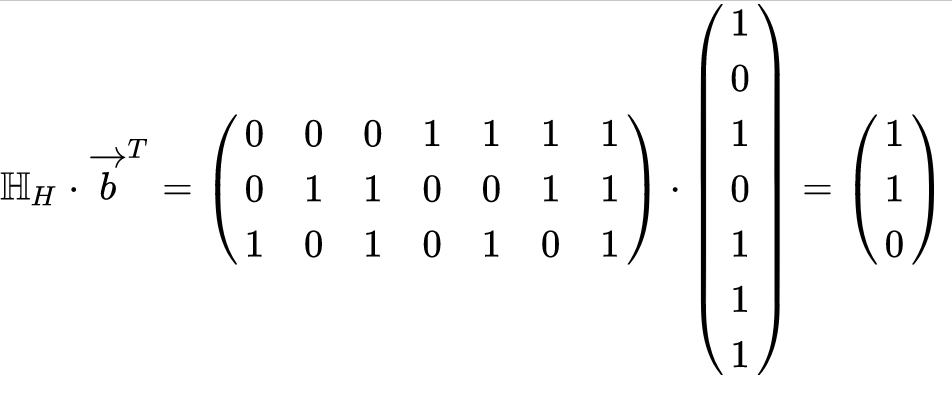
Syndrom 110 je v binární soustavě číslo 6 a vidíme, že chybu skutečně můžeme opravit překlopením jedničky na nulu na šesté pozici přijaté zprávy. Hammingův kód je tedy samoopravný a to s mnohem menší redundancí než ztrojení. Pro účely tohoto článku vůbec není potřeba znát a chápat matematiku, která za tím je, tyhle příklady měly jen vybudovat základní intuici o tom, že v komunikaci má redundance svoji užitečnou úlohu, kterou ale může plnit s různou efektivitou.
Hammingův prostor
Zajímavá na hammingově kódu je geometrická představa toho, jak funguje. V akademickém slangu se totiž procesu opravy přijaté zprávy říká “navlékání kódu na krychli”. Tento výraz odkazuje k tomu, že jednotlivá validní kódová slova (skupiny znaků) je možné si představit jako rohy krychle, což znamená, že vytyčují nějaký abstraktní prostor, kterému se říká hammingův prostor.

Přijatou zprávu je pak možné si představit jako bod někde v tomto prostoru. Pokud je zpráva přijata bez chyby, budou všechny její slova odpovídat právě hrotům krychle. Pokud ne, bude alespoň vidět, ke kterému hrotu jsou nejblíže a to je právě oprava, kterou hammingův kód navrhuje.
Opět není pro tento článek potřeba do detailu chápat, jak hammingův prostor funguje. Je potřeba si jen odnést intuici, že jeho redundance funguje tak, že ze všech možných kombinací znaků povoluje jen nějakou menší sadu, ze které sestaví takovou strukturu, kde se o jakékoli kombinaci znaků dá říct, jak daleko od nějakého stavu z té vybrané povolené sady je.
Zázrak, na který jsme si zvykli
Odbyli jsme si nutný úvod a můžeme se přesunout k věcem, se kterými se v programování setkáváme častěji. Vlastně mnohokrát každý den. (Omluvám se za tupou nedůvtipnost příkladu, moje invence se v tomhle článku vyčerpala na jiných věcech.)

Na obrázku je běžná, každodenní situace - program obsahuje chybu, zapomněli jsme deklarovat proměnnou. Editor zdrojového kódu chybu podtrhne, abychom věděli, co je potřeba opravit. Normálka, běžná věc… nebo ne? Zkuste o tom chvilku přemýšlet. Ne, vážně, koukejte na to a zkuste si představit, jak to může fungovat. Mělo by vám začít docházet, že to není tak jednoduché, jak to vypadá.
Programovací jazyky mají striktní syntaxi. Pokud není dodržena, překladač jazyka by měl prostě skončit s chybou. Maximálně může ještě říct, kam až se mu podařilo číst zdrojový kód správně. Červeně by tedy mělo být podtrženo všechno od řádky s chybou dál. Možná ještě hůř, jelikož překladač kvůli chybě nemůže rozumět funkci circleArea jako celku, nemůže přeci rozumět ani funkci circlesArea, která ji používá. Červeně by takto tranzitivně mělo být podtržené úplně všechno, celý program.
Překladač však neskončí na první chybě, dokonce se hned z další řádky zdá, jako kdyby věděl, co jsme chtěli udělat, jako kdyby naší chybu rovnou opravil, aby se nerozšířila dál do celého programu a jen nám teď blahoskolnně říká, že si to máme opravit i my. A skutečně, on nám v pomocné nabídce dokonce říká jak chybu opravit a nabízí, že ji sám opraví za nás:

Co je to za černou magii? Jak může počítač vědět, co jsme chtěli udělat? Vždyť zdrojový kód od nás je jeho jediná vstupní informace a nedá se validně zpracovat. Přemýšlí snad počítač nad programem sám za sebe? Má snad vlastní názor, co by v programu mělo být napsáno? A proč by jej v takovém případě nemohl za nás napsat rovnou celý? 1
Počítač vlastní myšlenky samozřejmě nemá. Vysvětlení spočívá v tom, že ačkoli o tom tak nejsme zvyklí přemýšlet, akt programování je ve skutečnosti aktem komunikace. Sdělujeme počítači, co po něm chceme a používáme k tomu jazyk. Sice programovací, ale pořád jazyk a jazyk je prostředkem komunikace. Počítač sám o sobě žádný názor nemá, to jen v našem kódu byl dostatek redundance, aby ho počítač mohl restaurovat tak, jak jsme sdělení skutečně zamýšleli.
Povaha redundance je v tomto případě podobná hammingovu prostoru. Strukturu určuje syntaxe jazyka na kterou se počítač snaží navléct náš zdrojový kód. Buď se mu to povede, nebo je alespoň vidět, jaké jsou nejbližší správné varianty.
Navrhnout syntaxi jazyka tak, aby tenhle proces byl co nejefektivnější a překladač za co nejmíň práce dokázal opravit co největší spektrum chyb, je jeden z velmi pokročilých aspektů designu programovacích jazyků. Nejde nějak definitivně “vyřešit”, protože to je od nějaké úrovně tradeoff. Směňujeme pracnost vytvoření kódu za pracnost hledání chyby v něm.
Pro ukázku opačného poměru pracností než v našem prvním příkladě nemusíme ani chodit do jiného jazyka. Stačí použít jiné jazykové konstrukty - lambdy, typovou inferenci atd. Když to přeženeme, může se nám klidně stát tohle:

V tomto (záměrně rozostřeném) kódu je jedna malá chyba. Kvůli úsporným výrazovým prostředkům tam však není dostatek redundance, aby mohl překladač chybu spolehlivě opravit nebo alespoň lokalizovat. Nezbývá mu proto nic, než podtrhnout celý velký blok a nechat hledání na nás. Když jsem u příkladu chyby ve výpočtu obsahu kruhu říkal, že by měl být červeně podtržený celý program, znělo to trochu přitažené za vlasy, že? Ale tohle je přesně ono.
Přecházíme na tvrdší drogy
Opravme tedy náš program nejjednodušším možným způsobem.

Ale teď, když vidíme, jak dobrej tenhle redundantní matroš je, začínáme přemýšlet, kde si obstarat další dávky.

Redundanci typu Hammingova kódu, tedy z očekávané struktury, nelze zvyšovat do nekonečna - už teď většina lidí nedokáže pochopit, k čemu sakra jsou středníky, když konec příkazu se dá ze syntaxe určit i bez nich. Možnosti tedy evidentně jsou, ale my bychom chtěli redundanci efektivní. Chtěli bychom kvalitní matroš a chtěli bychom ho hodně.

Jako obvykle k jakémukoli důležitému tématu existuje vtip buď v XKCD, v Simpsonech nebo ve Stopařově průvodci galaxií. Ohledně redundance je to tenhle citát ze Stopaře (zvýraznění je moje):
Jedna z věcí, které Fordu Prefectovi připadaly na lidech nejnepochopitelnějsí, byl zvyk neustále pronášet a opakovat naprosto očividná fakta, jako například to je ale krásně, ty jsi ale dlouhán, nebo jejej, vypadá to, že jsi spadl do desetimetrové studny, jsi v pořádku?
(One of the things Ford Prefect had always found hardest to understand about humans was their habit of continually stating and repeating the very very obvious, as in It’s a nice day, or You’re very tall, or Oh dear you seem to have fallen down a thirty-foot well, are you alright?)
Douglas Adams v tomto textu naráží na pozoruhodnou vlastnost reality a to, že realita prostě je. Realita ke svojí existenci nepotřebuje žádný komentář. Každý vidí realitu okolo sebe sám. Proto jakékoli tvrzení o realitě je zcela redundantní. Proč pak ale máme takové nutkání je tak často pronášet? K tomu se dostaneme, ale nejdřív si tento slibný zdroj redundance - prakticky jakékoli tvrzení o skutečnosti - trochu rozebereme.
Z Adamsova příkladu si asi každý dokáže představit, jak to vypadá v lidském jazyce. Jak ale takové redundantní tvrzení o skutečnosti může vypadat v programování? Tak třeba “Hodnota proměnné radiusSquared je číslo z množiny celých čísel v rozsahu [-2^63, 2^63-1]”.

Kupodivu máme pro tak složité tvrzení zkratku v podobě jediného slova long a je to stoprocentně redundantní tvrzení. Když se násobí dvě čísla z této množiny je výsledkem opět číslo z této množiny, tak je prostě operace násobení v procesoru definována. K deklaraci proměnné můžeme použít (a výše jsme použili) prosté slovo var, které o proměnné neříká vůbec nic než to, že existuje a program bude fungovat úplně stejně.
Další příklad samozřejmosti, kterou můžeme v programu explicitně zapsat navíc, je “Plocha jednotkové kružnice je zhruba 3.1415”.

Protože… tak to prostě je, což poprvé konstatoval už Archimedes ve starém Řecku a od té doby je to zapsané v každé učebnici matematiky a proto asi není zbytečnější činnnosti než to zopakovat i v našem programu.
Můžeme říct také něco míň vznešeného jako “Každý člověk v Česku má pro úřední účely přidělené jméno, příjmení a rodné číslo”.

Formálně je to vidět z právních norem, empiricky to můžeme konstatovat tím, že porovnáme toto tvrzení se skutečností. Je vidět, že redundantních tvrzení o skutečnosti zapisujeme do programů opravdu hodně, stejně jako ve vtipu ze stopaře, tak se teď pojďme vrátit k tomu proč.
Pravda jako kontrolní redundance sdělení
Dostali jsme se k jádru tohoto článku, které jsem rovnou destiloval do nadpisu kapitoly. Pravdivá, redundantní tvrzení jsme zvyklí vkládat do komunikace proto, že pokud jsou příjemcem vyhodnocena jako nepravdivá, je to spolehlivá indikace toho, že sdělení jako celek bylo přijato s chybou 2. Například:

Nepravdivost našeho tvrzení o hodnotě proměnné radiusSquared dovoluje počítači, jakožto příjemci našeho sdělení, aby v něm jednak detekoval chybu a jednak ji alespoň rámcově lokalizoval. Tím pádem ji pak může i v nějaké míře izolovat a v lepším případě i předpokládat opravu, jakkoli rozhodnutí o skutečné opravě musí nechat na nás 3.
Větší problém stále ještě představuje první z mých výchozích otázek - co to vlastně pravda je? Paradoxně přestože se tady snažím ukázat k čemu je, tak otázka co to je je neuzavřeným předmětem filosofických debat už celá tisíciletí. To není nadsázka! Ten termín, o kterém předpokládáme, že mu rozumí i tříleté děti, je skutečně velmi těžko postižitelný a teorií o jeho podstatě je více - korespondenční, koherenční aj. a každá z teorií je do jisté míry stavebním kamenem celého filosofického směru.
V kontextu programování a konkrétně výše uvedeného příkladu jsme jako podstatu pravdy použili Curry-Howardovou korespondenci, která (extrémně zjednodušeně) ukazuje ekvivalenci vztahu mezi tvrzením a jeho logickým důkazem v oboru formální logiky a mezi datovým typem a programem v oboru počítačové vědy. Výše uvedený příklad s datovými typy long a int, který se může zdát z praktického hlediska zcela nedostatečný pro vyjádření jakéhokoli složitějšího reálného tvrzení, je skutečně jen začátečnická ukázka. Curry-Howard ukazuje, že v datovém typu je možné zakódovat jakékoli tvrzení, jen to samozřejmě nebude v Javě, ale o tom až na konci.
Přes svůj název se Curry-Howard zdá příkladem koherenčního principu pravdy, logický důkaz ukazuje konzistenci zkoumaného výroku s ostatními výroky, jejichž pravdě věříme. Naproti tomu databázové schéma vypadá jako příklad korespondenčního principu pravdy, protože jeho pravdivost potvrzuje nebo vyvrací primárně skutečnost sama. Asserty v testech se pak zdají něco mezi. Tady už ale vařím z vody a proto už radši nebudu víc filosofům fušovat do řemesla a zkusím vyždímat do závěru něco jen z dřívějších odstavců.
K čemu je dobré zkoumat k čemu je to dobré?
Proč jsme se pustili do tohohle mentálního cvičení popisu pravdy z pohledu Shannona místo Platóna? Proč jsme prozkoumávali programování v termínech komunikace místo datových typů, unit testů a schémat?
Primárně jsem chtěl co nejdůkladněji ukázat, že redundance v komunikaci je tradeoff. Je to práce navíc nejen při prvotním sdělení, ale hlavně při všech změnách. Vždy, když chceme sdělení změnit, musíme předělat všechny nadbytečná tvrzení v něm, aby i v novém sdělení zůstala pravdivá. Výměnou za tuto pracnost dostáváme odolnost sdělení proti chybám.
Dál jsem chtěl ukázat, že tento princip existuje v komunikaci nezávisle na formě, je přítomen v binárních kódech, v programovacím jazyce i v lidské komunikaci. A v tom posledním je zakopaný pes. Je extrémně obtížné zvolit v programování ten tradeoff inženýrsky nezaujatě, když jej zvažujeme v komunikaci lidské mnohokrát každý den, celý svůj život. Ve skutečnosti je tato volba jedním ze základních stavebních kamenů naší osobnosti.
Například když je vaším povoláním politika, vyhýbáte se pravdě jako čert kříži. Nemusí to být jen proto, že jste zkorumpovaný zloděj, ale proto, že nedílnou součástí reálné politiky jsou neustále se měnící oportunistické kompromisy a každou pravdu vyřčenou navíc v jedné situaci je v situaci jiné potřeba pracně opravovat, aby pravdou zůstala, jinak voliči znejistí. Nejlepší je pak neříkat navíc vůbec nic, a nechat to tak, že věci prostě jsou tak jak jsou.
Na opačném konci spektra je pak třeba citát Jana Husa “hledej pravdu, slyš pravdu, uč se pravdě, miluj pravdu, říkej pravdu, drž pravdu, braň pravdu až do smrti”, protože jako šiřitel náboženského hodnotového systému nemá problém s příliš častými změnami, ale aby se jeho obsah během tiché pošty ve společnosti příliš nepokroutil. K tomu náboženství slouží kvanta doprovodných textů omýlajících stále stejné desatero nebo vyzdvihovaná jednota skutečných osudů s deklarovanými hodnotami. Kontrolní redundance koherenční i korelační.
To jsou samozřejmě ilustrace extrémů celého spektra, ale někde na tom spektru má každý z nás vysezené oblíbené a většinou dost statické místo, které odpovídá jeho nátuře a zkušenostem, jeho vlastnímu osudu. 4
To nejmenší, co by vám tento článek měl pomoci chápat lépe, jsou diskuze o silném a slabém, resp. statickém a dynamickém programování. Na základní úrovni můžeme argumentovat co je lepší na základě jejich výhod a nevýhod. Na vyšší úrovni si z článku můžeme vzít to, že redundance v podobě tvrzení o datových typech je vlastně tradeoff a jako takový je pro vyhodnocení nejdůležitější kontext situace. Nakonec bychom ale měli pochopit, že možnost volby v této otázce je jen iluzorní. Každý totiž stejně bude tíhnout k tomu říkat pravdy právě tolik, kolik je zvyklý ve svém každodenním životě a použitý jazyk mu v tom může jen bránit nebo pomáhat.
Dá se dokázat, že program neobsahuje chyby?
Mně osobně ale tohle zamyšlení pomohlo hlavně vyjasnit problematiku programovacích jazyků typu Coq, které tvrdí, že umožňují dokázat, že program neobsahuje chybu. Na jednu stranu jsem věřil, že to jejich autoři neříkají jen tak. Na druhou stranu je ale evidentní, že do hlavy programátorovi nikdo nevidí a proto nikdo a už vůbec ne stroj, nemůže posoudit, jestli se program chová tak, jak programátor zamýšlel, což je moje chápání bezchybnosti.
Teď už rozumím, že tento zdánlivý rozpor má jednoduché vysvětlení. Dokazovače opravdu nemohou sami o sobě zaručit “bezchybnost” programu, ale programátor pomocí nich může vyplodit takové množství redundantních tvrzení, že pokud budou všechny konzistentní, pravděpodobnost neočekávaného chování programu se bude limitně blížit nule.
Redundantních tvrzení může být dokonce tolik, že někdy se dá implementace zpětně odvodit jen z tvrzení o ní, to je podstata slavného paperu Theorems for free. To je odpověď na řečnickou otázku, zda by tedy počítač nemohl napsat rovnou celý program za nás, kterou jsme si položili výše u návrhů IDE na opravu chybějící deklarace proměnné. Může, ale musíme mu naše očekávání popsat v takové podrobnosti, že jej splňuje právě jedna implementace. Jak praktické to je ať si posoudí každý sám.
Už jen mlhavě pak tuším, že někde o hodně dál budou další poklady teoretické informatiky jako Kolmogorova komplexita, ale to už je zcela mimo mojí úroveň a může to být úplně mimo. Možná za dalších deset let?
-
Teaser: ano může! Ale více až na konci článku. ↩
-
Je zajímavé uvědomit si, že je jedno, jestli chyba vznikla mechanicky při vkládání zprávy skrz klávesnici nebo už při vlastní formulaci myšlenek v našem mozku. Svádí to k otázce, zda akt myšlení není vlastně jen aktem komunikace. Minimálně by to bylo v souladu s tím, že se u většiny lidí myšlení odehrává skrz onen vnitřní hlas, resp. dialog. ↩
-
Protože zpětnou vazbou o chybě dává nový podnět našemu myšlení viz poznámka 2. Programování jako mechanické rozšíření našeho myšlení, jako nástroj mentální práce, jsem se snažil popsat už dříve. ↩
-
Trklo mě to kdysi na krásném programátorském příkladu. Zadání znělo načíst vstupní parametry programu z CSV s názvy sloupců v první řádce. Jeden programátor použil pro načtení řádku jako datovou strukturu mapu, druhý definoval třídu s atributy odpovídajícími sloupcům. U prvního jsme samozřejmě řešili prapodivné chyby programu v důsledku špatné konfigurace, u druhého zas když zadavatelé do CSV přidali sloupce x1 až x100 používané každý v různých situacích. To, co mi došlo, nebylo, kdo z nich to udělal lépe, ale že jejich řešení jsou víc než co jiného reflexe jejich lidských povah, jak jsem je znal. Svých způsobů se proto samozřejmě nevzdali po konfrontaci s problémy a bylo by pošetilé je k tomu nutit. ↩